最近我把一些跑在公有云上的RouterOS替换成了正常的Linux发行版。大多数RouterOS原有的路由功能都可以通过Linux标准的工具加以实现(虽然Linux当路由器总有一个令人诟病的问题就是不支持配置自动保存和开机自动恢复,需要自己写一大堆脚本和配置),但是有一件事情让我头疼了一会儿:Linux的GRE隧道原生不支持keepalive。
GRE Keepalive协议解析
GRE是一个非常简单的无状态隧道协议。众所周知,一切网络问题都可以用加一个数据包头来解决。GRE就干这么一件事情:这头发包的时候前面加上一个头,那边收到包以后把头拆掉,中间所有的路由器就成为了工具路由器,逻辑上就都不存在了。相比其它隧道协议,它有几点特性:
- 虽然它是一个点对点隧道,但是它支持multicast
- 虽然它的包头比IPIP6和IP6IP等简单粗暴的隧道要大一点儿,但是它支持MPLS之类的协议
- 无状态,不需要握手和协商,方便硬件(ASIC)实现封包和拆包
- 被绝大多数企业级路由器(黑盒子)支持,甚至可能是某些企业级路由器上唯一支持的隧道协议
所以在网络工程上,GRE的应用相当广泛。但是无状态这个特性在实践中会带来一些问题,比如很多路由器系统对静态路由是只支持根据接口的up和down状态实现路由failover的,GRE接口配置完以后永远处于up状态,就会给容灾架构的设计带来很大困扰。BFD协议可以用来检测隧道对端是否可达,但是也要和动态路由协议联动才有意义。要是有一种方法能让GRE隧道自己知道自己是否可以连通对端设备,然后改变自己的端口状态,那它就能完美符合一个路由器对接口这一概念的抽象了。GRE keepalive就是在这样的想法之下诞生的。
在企业环境下,任何新功能的引入都得考虑和旧设备(尤其是那些十年前就装在那然后没人敢碰一下的旧设备)的兼容性问题。而且GRE不存在握手过程,所以也没有办法判断对方是否支持特定的功能。GRE keepalive利用了路由器对隧道封装的数据包的处理逻辑,巧妙地让不支持GRE keepalive的设备也能不知情地响应keepalive包。我们来看一下路由器是怎么处理一个GRE包的:

GRE包结构(图片来自Red Hat Developers Blog)
这个包会通过物理接口发送到路由器的IP协议栈。协议栈见到IP头之后的GRE头,会首先匹配本机的GRE隧道配置,找到相应的隧道,否则丢弃。接下来是解封装过程,前面的IP头和GRE头都被丢弃。解封装结束以后,拆出来的数据包重新回到IP协议栈,根据内部IP头重新执行路由查找和包转发过程。那么如果我们在GRE隧道里面封装一个IP包,这个包的源地址是对端的隧道端点IP,目标地址是我方端点IP,然后把这个包从GRE隧道内发出去,会发生什么呢?显然,对端对GRE做解封装处理以后,这个包会经过物理链路重新路由回本机。那么,如果解封装以后的包的payload部分正好是一个长度为0的GRE包,本机的GRE处理程序就会收到一个长度为0的GRE包,从而判断对方仍然在线。GRE keepalive就是通过这样的机制,在不影响协议兼容性的情况下,实现了对网络连通性的检测。
Linux为什么不能原生支持GRE Keepalive
Linux的IP协议栈会对所有进来的包先做一些基础的检查以确定这个包是否合法,检查规则中包括了一条:收到的包的源IP不能是本机IP。在 net/ipv4/fib_frontend.c 的 __fib_validate_source 函数里我们可以看到检查的具体逻辑。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
/* Given (packet source, input interface) and optional (dst, oif, tos): * - (main) check, that source is valid i.e. not broadcast or our local * address. * - figure out what "logical" interface this packet arrived * and calculate "specific destination" address. * - check, that packet arrived from expected physical interface. * called with rcu_read_lock() */ static int __fib_validate_source(struct sk_buff *skb, __be32 src, __be32 dst, u8 tos, int oif, struct net_device *dev, int rpf, struct in_device *idev, u32 *itag) { struct net *net = dev_net(dev); struct flow_keys flkeys; int ret, no_addr; struct fib_result res; struct flowi4 fl4; bool dev_match; fl4.flowi4_oif = 0; fl4.flowi4_iif = l3mdev_master_ifindex_rcu(dev); if (!fl4.flowi4_iif) fl4.flowi4_iif = oif ? : LOOPBACK_IFINDEX; fl4.daddr = src; fl4.saddr = dst; fl4.flowi4_tos = tos; fl4.flowi4_scope = RT_SCOPE_UNIVERSE; fl4.flowi4_tun_key.tun_id = 0; fl4.flowi4_flags = 0; fl4.flowi4_uid = sock_net_uid(net, NULL); no_addr = idev->ifa_list == NULL; fl4.flowi4_mark = IN_DEV_SRC_VMARK(idev) ? skb->mark : 0; if (!fib4_rules_early_flow_dissect(net, skb, &fl4, &flkeys)) { fl4.flowi4_proto = 0; fl4.fl4_sport = 0; fl4.fl4_dport = 0; } if (fib_lookup(net, &fl4, &res, 0)) goto last_resort; if (res.type != RTN_UNICAST && (res.type != RTN_LOCAL || !IN_DEV_ACCEPT_LOCAL(idev))) goto e_inval; fib_combine_itag(itag, &res); dev_match = fib_info_nh_uses_dev(res.fi, dev); /* This is not common, loopback packets retain skb_dst so normally they * would not even hit this slow path. */ dev_match = dev_match || (res.type == RTN_LOCAL && dev == net->loopback_dev); if (dev_match) { ret = FIB_RES_NHC(res)->nhc_scope >= RT_SCOPE_HOST; return ret; } if (no_addr) goto last_resort; if (rpf == 1) goto e_rpf; fl4.flowi4_oif = dev->ifindex; ret = 0; if (fib_lookup(net, &fl4, &res, FIB_LOOKUP_IGNORE_LINKSTATE) == 0) { if (res.type == RTN_UNICAST) ret = FIB_RES_NHC(res)->nhc_scope >= RT_SCOPE_HOST; } return ret; last_resort: if (rpf) goto e_rpf; *itag = 0; return 0; e_inval: return -EINVAL; e_rpf: return -EXDEV; } |
这样一来,对端即使给Linux发送了GRE keepalive包,只要进了Linux的IP协议栈,就会被丢弃。
Linux上的GRE Keepalive实现
实现的思路其实很简单,我们只要在包进到IP协议栈之前先把它抓到,想办法自己处理完,然后发回去即可。几年前有人写过一个Perl脚本,实现方法是pcap抓包,然后用户态开一个raw socket回复。不过我觉得,现在都2020年了,是时候用点新方法了。 让我们来看一看,有哪些方法能抓到这个包。
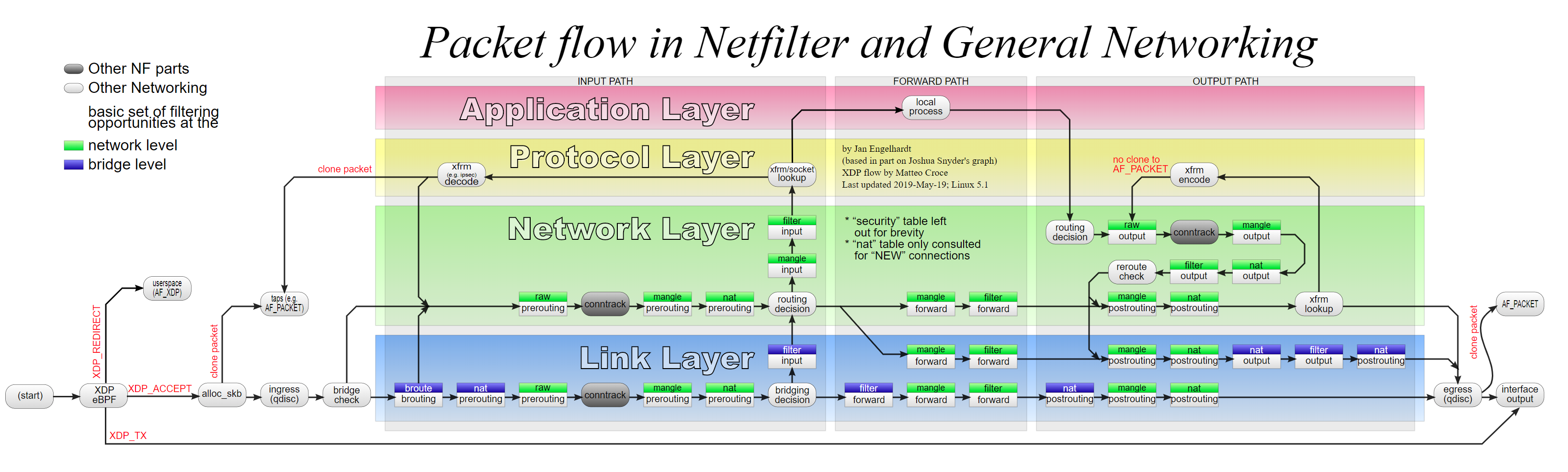
Netfilter包处理路径(图片来自Wikimedia Commons)
从图上可以看到,其实方法就两个;在 alloc_skb 之后用 AF_PACKET 抓包的方法跟libpcap的 PF_PACKET 就差一个二层协议栈,好像没有什么新意,那就只剩下一个选择:使用位于流程图最左边的XDP/eBPF机制。XDP的原理很简单:内核里面有一个VM负责执行eBPF程序,你把你写的钩子函数编译成eBPF IR加载进内核。包进来的时候,你的钩子函数就会被调用,内核根据钩子函数的返回值决定做什么操作。返回值总共有五种选项:
- XDP_PASS 表示这个包会按照流程继续走下去
- XDP_DROP 表示这个包应该被丢掉(CloudFlare就是用它实现了超高性能的丢包)
- XDP_TX 表示这个包应该被原路发回
- XDP_REDIRECT 表示这个包应该被发送到其它接口上
- XDP_ABORT 表示程序出错,无法处理(包会被丢掉)
另外,钩子函数还可以对当前数据包进行任意修改,包括更改其内容,以及改变包的长度。libBPF提供了一些方便的工具函数来帮你做这些事情。这样我们就有了实现思路:首先匹配外部的GRE头和payload里面的长度为0的GRE头,识别到这是一个keepalive包以后,通过调整长度削掉外部IP头和GRE头,最后返回一个 XDP_TX ,包就回去了。不过,这事儿虽然说着简单,有一些大坑还是需要提前做个心理准备的。
刚开始写eBPF程序的时候,配置环境是个很让人头疼的问题。如果不想在源代码里面塞一整个Linux内核,可以按照xdp-tutorial的方法单独把libBPF拿出来链接。不过那份tutorial里面有一些东西可能是你在自己写项目的时候会想要改一下或者删掉的。
因为eBPF程序是在内核里跑的,能直接操作内核的内存空间,因此内核会对程序的安全性有很高的要求。eBPF程序加载前,内核的静态检查器会对程序做检查。程序本身不难,但是这静态检查可麻烦了。首先,访问任何内存地址之前,需要自己检查访问是否越界。XDP钩子函数接收到的参数里面包含了当前数据包的起始位置和结束位置指针,每次如果要往后读,必须先检查要解引用的指针是否超出了结束位置。其次,程序执行时不允许向前跳转,例如使用goto跳转到上方的代码段,或者任何形式的循环。如果一定要使用循环,需要让编译器在编译期展开。静态检查器报错的时候只会告诉你出错位置附近的几行IR汇编,我们可以用 llvm-objdump -S program.o 反汇编来查找对应的C源代码位置。
Linux的隧道分成TAP和TUN两个大类。如果你的XDP程序加载到TAP隧道上,那么你会收到一个Ethernet包。如果是TUN隧道呢,那么收到的直接是IP包,没有前面的Ethernet头。GRE隧道是TUN隧道,而GREv6(ip6gre)是个TAP隧道,当时在做GREv6支持的时候这让我困惑了好一会儿。最开始我还实现了个猜测里面是Ethernet包还是IP包的过程,后来转念一想,创建隧道的时候隧道类型不是可预知的吗,为什么不写两个函数,在创建隧道的时候加载对应的那个呢?于是就大幅简化了程序结构。
最后,这是写好的程序:Jamesits/linux-gre-keepalive
参考资料: