2017年发生了两件大事:
- FRRouting项目启动,把原来需要打patch才能在Quagga上使用的ldpd合并进了主线
- Cumulus公司把自己的VRF实现贡献给了Linux内核
Linux终于获得了能用的原生的MPLS(L3VPN)和VRF支持。不过三年以后,MPLS配置的完整文档尚付阙如。近日我经过研究和阅读各种零散的资料,成功在测试环境中配置了一个标准的MPLS核心网络架构,因此写一篇文章来分享配置过程以及路上遇到的各种坑。
MPLS?
只玩IP路由,不怎么接触大型运营商网络的同学们可能会对MPLS这个技术有些陌生。如果要打一个简单的比方,MPLS(L3VPN)就像是三层意义上的VLAN Trunking:路由器上把三层接口加入VRF(对应交换机上的VLAN),每个路由器上可以有多个虚拟的路由表(对应交换机上的ARP表),核心路由器之间传送的数据报文前面会被加上MPLS标签(对应交换机上的VLAN标签)保证多个路由表内的数据互不干扰。MPLS的好处有很多:
- 用同一组路由器为不同的客户提供不同种类的服务
- 允许不同的客户网使用相同的IP地址段
- 核心节点不需要查找路由表,只需要做简单的MPLS标签替换工作,增加了包转发性能
- 核心节点不需要保存客户的全量路由表,只需要负责转发,节约内存
- 可以实现在客户无感知的情况下把多地的同一客户设备连接起来,不同客户互相隔离
- 简化复杂的三层配置
- 可以设置特定流量走特定路径,方便负载均衡和冗余
这么好的协议,当然会有一些前提要求。MPLS是一个2.5层协议,也就是说它需要运行在二层之上。所以如果要启用MPLS,首先整个核心网路由器之间需要用支持二层的方式(例如Ethernet)连接,或者使用对MPLS做了特殊支持的非二层隧道(RFC2547bis,例如GRE或L2TP)。MPLS的数据报文有8字节的头部,因此你可能需要适当增大核心网的MTU。
MPLS核心网的路由器一般分为两类:P(Provider),即不连接任何客户设备的路由器,以及PE(Provider Edge),即连接客户设备的路由器。直接连接到PE的客户设备称为CE(Customer Edge)。其它理论知识在此就不细讲了,简单来说,MPLS的配置需要以下几步:
- 给每台P和PE设置loopback端口的固定IP
- 通过IGP让所有P和PE之间loopback IP都可以互相ping通
- 在每台P和PE上启动MPLS处理功能和LDP服务
- 在PE上配置iBGP,启动MP-BGP功能
- 在PE上配置VRF,并且将连接客户的端口加入相应的VRF
- 把客户的路由重分发到核心网的VRF路由表
接下来,我用一个简化版的实验室环境来演示一下Linux上MPLS的实际配置过程。
MPLS!
要解决的问题
假设我们是一个跨城市的小ISP,提供一种把客户在两个城市之间的站点连接起来的业务。业务的实现方式很简单,客户在两个城市分别拉一根网线到我们在同一城市的路由器,配置好IP,然后客户在两个城市的站点就魔法般互相接通了。有一天突然来了两个客户——暂且称之为customer1和customer2好了——都要购买我们的服务,巧的是,他们内网用的IP段是一模一样的。如果我们的核心网络使用传统IP技术互联的话,两个客户的内网可能就互通了,并且还会互相打架。但是如果我们的核心网络使用了MPLS技术,这个配置不费吹灰之力就可以完成。
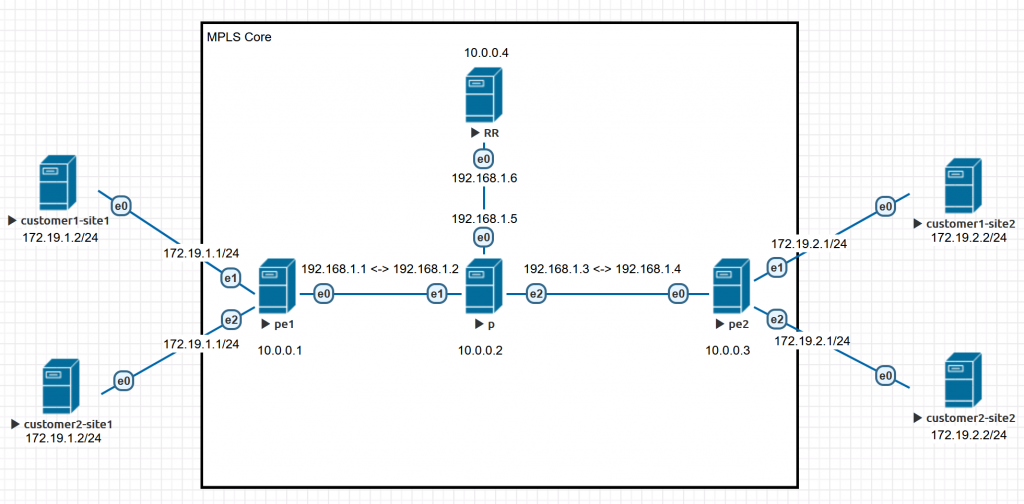
说明:
- 所有连线均为以太网连接
- 核心网之间设备互联使用192.168.1.0/24段(点对点配置)
- 核心网每个设备有一个10.0.0.x/32的IP用于loopback
- 图片上的e0/e1/e2分别对应下面配置里的ens3/ens4/ens5
暂时不解决的问题
为了限制篇幅,以下问题本文不深入讨论:
- MTU不匹配问题(建议PE上MSS全部clamp到1410)
- CE和PE之间的动态路由协议
- Linux网络栈的开机自动配置(动态创建的interface,sysctl配置之类的重启以后都会丢,如何使用网络管理软件在开机的时候把它们都正确配置起来就留给读者作为练习了。)
- VPLS(Linux目前还不支持pseudowire接口)
LittleWolf的《[ Linux ] 使用 Debian Linux 构架 MPLS L3 网络》一文中演示了核心网络使用IS-IS以及CE和PE之间使用BGP实现动态路由的配置,推荐和本文一起阅读。
参考软件
图中所有设备使用以下软件:
- Debian 10(Linux 4.19.0)
- iproute2 4.20.0
- FRRouting 7.2.1(FRRouting提供的deb包)
MPLS配置流程
以下每个代码块开头用#标识该代码块在什么环境下运行。其中:
# linux shell表示在Linux原生shell(bash等)下运行# vtysh表示在vtysh下运行# vtysh config表示在vtysh的配置模式(conf t)下运行
设置操作系统
安装FRRouting:
|
1 2 3 4 5 |
# linux shell curl -s https://deb.frrouting.org/frr/keys.asc | sudo apt-key add - echo deb https://deb.frrouting.org/frr buster frr-stable | sudo tee -a /etc/apt/sources.list.d/frr.list apt update apt install frr |
启动FRRouting:
|
1 2 3 4 |
# linux shell sed -i "s/=no/=yes/g" /etc/frr/daemons systemctl enable frr systemctl restart frr |
加载MPLS内核模块:
|
1 2 3 4 5 6 7 8 9 10 11 |
# linux shell modprobe mpls_router modprobe mpls_iptunnel modprobe mpls_gso modprobe dummy cat >/etc/modules-load.d/mpls.conf <<EOF mpls_router mpls_iptunnel mpls_gso dummy EOF |
内核MPLS基础配置:
|
1 2 3 4 5 6 7 8 9 10 11 |
# linux shell cat >/etc/sysctl.d/90-mpls-router.conf <<EOF net.ipv4.ip_forward=1 net.ipv6.conf.all.forwarding=1 net.ipv4.conf.all.rp_filter=0 net.mpls.platform_labels=1048575 net.ipv4.tcp_l3mdev_accept=1 net.ipv4.udp_l3mdev_accept=1 net.mpls.conf.lo.input=1 EOF sysctl -p /etc/sysctl.d/90-mpls-router.conf |
核心网IP网络配置以及设置Loopback IP
Loopback IP其实不是必需的,如果你想给每个端口分别配置各种协议的源IP其实也行。但是只要你的网络稍微有一点规模,配置一下loopback IP可以少打很多其它配置,而且能避免router id不稳定导致的动态路由协议玄学问题。
P
|
1 2 3 4 5 6 7 8 9 10 |
# linux shell ip link set ens3 up ip link set ens4 up ip link set ens5 up ip addr add 192.168.1.5 peer 192.168.1.6 dev ens3 ip addr add 192.168.1.2 peer 192.168.1.1 dev ens4 ip addr add 192.168.1.3 peer 192.168.1.4 dev ens5 ip link add dummy0 type dummy ip link set dummy0 up ip addr add 10.0.0.2/32 dev dummy0 |
PE1
|
1 2 3 4 5 6 7 8 |
# linux shell ip link set ens3 up ip link set ens4 up ip link set ens5 up ip addr add 192.168.1.1 peer 192.168.1.2 dev ens3 ip link add dummy0 type dummy ip link set dummy0 up ip addr add 10.0.0.1/32 dev dummy0 |
PE2
|
1 2 3 4 5 6 7 8 |
# linux shell ip link set ens3 up ip link set ens4 up ip link set ens5 up ip addr add 192.168.1.4 peer 192.168.1.3 dev ens3 ip link add dummy0 type dummy ip link set dummy0 up ip addr add 10.0.0.3/32 dev dummy0 |
RR
|
1 2 3 4 5 6 |
# linux shell ip link set ens3 up ip addr add 192.168.1.6 peer 192.168.1.5 dev ens3 ip link add dummy0 type dummy ip link set dummy0 up ip addr add 10.0.0.4/32 dev dummy0 |
检查
两两邻接的路由器互相ping对面的接口IP应该能够ping通。
在核心网络中启动IGP
IGP的目的是让loopback IP互相能通。因为我不会别的协议为了简单起见,这里以OSPF为例,全默认配置,所有路由都放到Area 0就可以了。因为上面端口配置部分我们给所有核心网路由器之间的以太网链路配置了点对点连接,OSPF这边需要改一下每个接口的类型。
P
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# vtysh config interface ens3 ip ospf network point-to-point interface ens4 ip ospf network point-to-point interface ens5 ip ospf network point-to-point router ospf ospf router-id 10.0.0.2 redistribute connected redistribute static network 10.0.0.0/24 area 0 network 192.168.1.0/24 area 0 |
PE1
|
1 2 3 4 5 6 7 8 9 |
# vtysh config interface ens3 ip ospf network point-to-point router ospf ospf router-id 10.0.0.1 redistribute connected redistribute static network 10.0.0.0/24 area 0 network 192.168.1.0/24 area 0 |
PE2
|
1 2 3 4 5 6 7 8 9 |
# vtysh config interface ens3 ip ospf network point-to-point router ospf ospf router-id 10.0.0.3 redistribute connected redistribute static network 10.0.0.0/24 area 0 network 192.168.1.0/24 area 0 |
RR
|
1 2 3 4 5 6 7 8 9 |
# vtysh config interface ens3 ip ospf network point-to-point router ospf ospf router-id 10.0.0.4 redistribute connected redistribute static network 10.0.0.0/24 area 0 network 192.168.1.0/24 area 0 |
检查
核心网里的每台路由器使用自己的loopback IP去ping任意其它路由器的loopback IP应该都能通。例如在PE1上ping RR:
|
1 2 |
# linux shell ping -I 10.0.0.1 10.0.0.4 |
启动MPLS处理功能和LDP服务
每个有MPLS流量经过的接口都要启用MPLS功能,并且打开LDP。
P
|
1 2 3 4 |
# linux shell sysctl net.mpls.conf.ens3.input=1 sysctl net.mpls.conf.ens4.input=1 sysctl net.mpls.conf.ens5.input=1 |
|
1 2 3 4 5 6 7 8 |
# vtysh config mpls ldp router-id 10.0.0.2 address-family ipv4 discovery transport-address 10.0.0.2 interface ens3 interface ens4 interface ens5 |
PE1
|
1 2 |
# linux shell sysctl net.mpls.conf.ens3.input=1 |
|
1 2 3 4 5 6 |
# vtysh config mpls ldp router-id 10.0.0.1 address-family ipv4 discovery transport-address 10.0.0.1 interface ens3 |
PE2
|
1 2 |
# linux shell sysctl net.mpls.conf.ens3.input=1 |
|
1 2 3 4 5 6 |
# vtysh config mpls ldp router-id 10.0.0.3 address-family ipv4 discovery transport-address 10.0.0.3 interface ens3 |
RR
其实RR本来不用被掺和进这个MPLS网络的,它只要到所有PE的IP网络都通即可。但是FRRouting当前版本的LDP daemon不支持Downstream Unsolicited模式,只能运行在 Downstream-on-Demand模式下,所以如果RR不配置MPLS的话,从PE到RR方向的包会在P上因为转发表里面没有该条目而被丢掉。迫不得已,我们把RR也拖下水。
|
1 2 |
# linux shell sysctl net.mpls.conf.ens3.input=1 |
|
1 2 3 4 5 6 |
# vtysh config mpls ldp router-id 10.0.0.4 address-family ipv4 discovery transport-address 10.0.0.4 interface ens3 |
如果不想把RR拉下水呢,可以在RR上不运行OSPF,让和RR直连的那台P或者PE把到RR的静态路由分发到网内。或者可以用 label local allocate for 强制LDP分发到RR的prefix的label。
检查
两两邻接的路由器之间LDP会话应该已经成功建立。例如在P上:
|
1 2 3 |
# vtysh show mpls ldp neighbor |
应该会看到三个会话:
|
1 2 3 4 |
AF ID State Remote Address Uptime ipv4 10.0.0.1 OPERATIONAL 10.0.0.1 09:40:33 ipv4 10.0.0.3 OPERATIONAL 10.0.0.3 09:40:01 ipv4 10.0.0.4 OPERATIONAL 10.0.0.4 08:18:28 |
并且所有路由器之间使用loopback IP互相ping应该仍然能通。(这个时候使用loopback IP的包已经会从MPLS网络转发,而不是走原来的IP网络了。)
在PE上配置iBGP
iBGP只需要在PE上配置,P完全不用配置,这是MPLS的好处之一:核心路由器只需要处理转发流量,不需要再费心思存储路由表和处理路由表更新。iBGP呢用full mesh也行,RR也行;既然图片上画了RR,这里就用RR的配置方法:所有PE和RR启动BGP会话。本文只演示IPv4的配置方法,对每个会话禁用IPv4 unicast的SAFI,启动IPv4 VPN(VPNv4)的SAFI。IPv6配置方法类似,启用IPv6 VPN的SAFI即可,不再赘述。
对于生产环境而言,单台RR是一个非常容易出问题的单点故障源。Packet Pusher有很不错的关于RR冗余架构设计的文章可供参考。
RR
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# vtysh config router bgp 65000 no bgp default ipv4-unicast neighbor 10.0.0.1 remote-as 65000 neighbor 10.0.0.1 update-source dummy0 neighbor 10.0.0.3 remote-as 65000 neighbor 10.0.0.3 update-source dummy0 address-family ipv4 vpn neighbor 10.0.0.1 activate neighbor 10.0.0.1 route-reflector-client neighbor 10.0.0.3 activate neighbor 10.0.0.3 route-reflector-client |
PE1和PE2
|
1 2 3 4 5 6 7 |
# vtysh config router bgp 65000 no bgp default ipv4-unicast neighbor 10.0.0.4 remote-as 65000 neighbor 10.0.0.4 update-source dummy0 address-family ipv4 vpn neighbor 10.0.0.4 activate |
检查
BGP会话应当正常建立。
在PE上配置VRF
Linux配置VRF有两种方法,一种是net namespace,一种是VRF interface。前者是Linux专有的抽象方式,在多个net namespace之间实现路由泄露和数据交换很不方便,但是对于容器和半虚拟化等应用场景很实用。由于这里只是把Linux系统作为路由器使用,本文选择了相对更加贴近商业路由器系统设计的VRF interface模式。
配置的思路很简单:每个VRF interface在创建的时候会被关联到一个路由表(由table ID唯一标识),然后就像把二层端口加入bridge一样,你可以把三层端口加入VRF。为了保证新建立的路由表能被特定程序读取,这边默认会往路由表写一条metrics设为最大值的默认路由,这样既能保证路由表存在,又不影响其它路由的正常使用。
为了防止操作失误,我们在每台PE上对同一个客户使用同样的VRF名称和table ID。
PE1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# linux shell # customer 1 ip link add customer1 type vrf table 100 ip link set customer1 up ip route add vrf customer1 unreachable default metric 4278198272 ip -6 route add vrf customer1 unreachable default metric 4278198272 ip link set ens4 vrf customer1 ip link set ens4 up ip addr add 172.19.1.1/24 dev ens4 # customer 2 ip link add customer2 type vrf table 200 ip link set customer2 up ip route add vrf customer2 unreachable default metric 4278198272 ip -6 route add vrf customer2 unreachable default metric 4278198272 ip link set ens5 vrf customer2 ip link set ens5 up ip addr add 172.19.1.1/24 dev ens5 |
PE2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# linux shell # customer 1 ip link add customer1 type vrf table 100 ip link set customer1 up ip route add vrf customer1 unreachable default metric 4278198272 ip -6 route add vrf customer1 unreachable default metric 4278198272 ip link set ens4 vrf customer1 ip link set ens4 up ip addr add 172.19.2.1/24 dev ens4 # customer 2 ip link add customer2 type vrf table 200 ip link set customer2 up ip route add vrf customer2 unreachable default metric 4278198272 ip -6 route add vrf customer2 unreachable default metric 4278198272 ip link set ens5 vrf customer2 ip link set ens5 up ip addr add 172.19.2.1/24 dev ens5 |
把客户的路由重分发到核心网的VRF路由表
限于篇幅,只演示connected路由的重分发,不在PE和CE之间配置动态路由协议了。这里要做的事情是,在每个VRF上创建一个空的(没有peer的)BGP配置,把VRF内要分发的路由先导入该BGP的RIB,然后让它把路由表打上特定route distinguisher community以后导入主BGP的RIB。
为了防止操作失误,我们在每台PE上对同一个客户使用同样(和table ID对应)的RT和RD。另外需要注意的是,FRRouting的vtysh虽然语法上和Cisco IOS很像,但是在这里是不太一样的。
PE1和PE2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# vtysh config router bgp 65000 vrf customer1 address-family ipv4 unicast redistribute connected redistribute static label vpn export auto rd vpn export 65000:100 rt vpn both 65000:100 export vpn import vpn router bgp 65000 vrf customer2 address-family ipv4 unicast redistribute connected redistribute static label vpn export auto rd vpn export 65000:200 rt vpn both 65000:200 export vpn import vpn |
配置的时候FRRouting会报一个错,不要惊慌,这是个bug,功能还是能用的。
检查
这时候我们应该可以在每个PE上看到每个VRF里面出现通过BGP重分发来的connected路由了。例如在PE1上:
|
1 2 |
# vtysh show ip bgp vrf customer1 |
应该会看到类似这样的输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BGP table version is 2, local router ID is 172.19.1.1, vrf id 9 Default local pref 100, local AS 65000 Status codes: s suppressed, d damped, h history, * valid, > best, = multipath, i internal, r RIB-failure, S Stale, R Removed Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path *> 172.19.1.0/24 0.0.0.0 0 32768 ? *> 172.19.2.0/24 10.0.0.3@0< 0 100 0 ? Displayed 2 routes and 2 total paths |
配置模拟的客户侧设备
为了模拟MPLS对不同客户相同IP段的隔离功能,我们把两个客户同一侧的设备的IP配置配成完全相同。
customer1-site1和customer2-site1
|
1 2 3 4 |
# linux shell ip link set ens3 up ip addr add 172.19.1.2/24 dev ens3 ip route add default via 172.19.1.1 |
customer1-site2和customer2-site2
|
1 2 3 4 |
# linux shell ip link set ens3 up ip addr add 172.19.2.2/24 dev ens3 ip route add default via 172.19.2.1 |
检查
首先我们确认同一个客户的两个站点之间可以互相ping通。由于我们的配置启用了PHP和TTL propagation,同一个客户的两台设备中间经过三台MPLS路由器以后会出现两跳非IP路由,所以如果我们使用traceroute或者mtr来测试的话会看到以下输出:
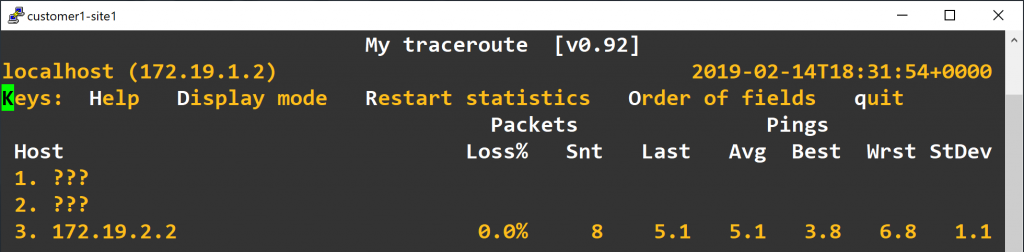
可惜的是,Linux部分支持RFC4884,完全不支持RFC4950,所以traceroute -e和mtr --mpls没法显示路上的MPLS详细信息。
如果想要简单地验证一下确实是同一个客户的两个站点被连接起来了的话,可以使用netcat启动一个简单的TCP聊天服务,只需要在一个客户的其中一个站点启动服务器:
|
1 2 |
# linux shell nc -l -p 8888 |
然后在同一个客户的另一个站点连接服务器:
|
1 2 |
# linux shell nc 172.19.2.2 8888 |
连接上以后,在两边输入任意字符并按回车,对端都会显示相同的字符。
MPLS……
Linux的发展史可以概括为一个小故事:某天你想要造个模型飞机玩,就照着真飞机的样子用木棍和纸片随手搭了一个起来放在后院;第二天起床一看,昨天随手搭的那个飞机已经被邻居开上了天,上面坐着十几二十个乘客,还有两三个人正趴在机翼上边维持平衡边修发动机呢。
“反正是免费提供的,摔下来也不关我事,管他呢。”你在心里默默地想,然后该干啥干啥去了。
致谢:
两位CCIE大佬对本文的写作做出了巨大贡献。
参考:
- Virtual Routing and Forwarding: Cumulus Linux
- VRF for Linux — a contribution to the Linux Kernel
- Using the Linux VRF Solution
- Configuring a VRF to work properly for FRR
- iproute2 commands for MPLS configuration
- LDP: FRRouting
- ldpd basic test setup
- frrouting/linux bgp mpls example
- LDP: Label allocation for “not connected” IP Prefix.
- BGP: FRRouting
- End-to-End MPLS Not Working On Docker Container
- Inconsistency in auto-derived RT value of EVPN show commands.
- MPLS及LDP协议基础
- MP-EBGP Configuration Example
- MPLS: Layer 3 VPNs Configuration Guide, Cisco IOS Release 15M&T
- Configuring a Basic MPLS VPN
- Troubleshooting Any Transport over MPLS Based VPNs
- How to Create a Simple Chat with netcat in Linux
Pingback引用通告: [ Linux ] 使用 Debian Linux 构架 MPLS L3 网络 | LittleWolf Network Universe
en3 en4 en5 接口是如何创建的, 且保证设置的IP地址对于其他P PE节点可以访问到。 我的实验环境是 云平台上的几台虚拟机
MPLS 下面需要是一个以太网连接或者支持 MPLS 的隧道协议(例如 GRE)。文中我用的测试环境全部是以太网连接。
拓扑A—-B—-C这样的连接关系
差不多是按上面的方案配完之后,尝试从A向C的lo接口IP发ping报文,但发现在经过B的时候,B没有向B-C接口转发
A主路由表上有C的lo接口IP的encap mpls的路由条目,但B上没有任何encap mpls条目
B上的ip -M route上的路由表看起来是正常的,但其实我也不太清楚什么样的算是正常的
是否有什么思路能解决为什么不转发的原因?
rp_filter因为我长期做ip base的策略路由,这个肯定是一直为0的,具体接口的mpls accept感觉应该也调成1了
如果你全网关闭了 PHP 功能的话,B 上确实不应该有 encap MPLS,因为 A 发出来的包已经 encap mpls 了,B 会直接收到 MPLS 包然后根据 MPLS 转发表转发,没有 encap 过程。
Debug 思路大概是这样:首先看 A 上面 ip 路由表,看去 C 的包被 encap 了具体哪个 label 以及下一跳是否正确;然后去 B 上 FRR 里面用 show mpls ldp ipv4 binding 命令查看 MPLS 转发表,根据 local label 对应 A 发过来的 label,检查 remote label(发给 C 的 label)和 nexthop 是否正确,以及该条条目 in use 是否为 yes。
续一下上次的问题(
在B能tcpdump到A发过来的mpls包,标签为52(MPLS (label 52, exp 0, [S], ttl 64)),
对应规则是ipv4 172.22.0.4/32 172.22.0.4 52 imp-null yes,
请问remote label为imp-null是否为预期的结果呢?
destination看起来都是正确的,nexthop如果这里应该显示C的loopback IP(每台机器上的discoveryIP都设置为loopback的IP了,只不过这里我没有用dummy接口,而是用了netplan无网卡的bridges来模拟loopback接口,感觉应该没什么关系)的话,那应该也是对的
B上的ip -M route的结果是
52 via inet 10.0.254.77 dev dev-BtoC proto ldp
这个倒是符合预期的
拓扑
A(lo 172.22.0.1)
B(lo 172.22.0.3)
C(lo 172.22.0.4)
如果你是从 A ping C 的 loopback IP 获得这样的结果,并且 PHP 开着的话,出现 imp-null 是合理的,因为这个包是直接到 C 本机的,所以 B 那里就会直接把 MPLS 头拆掉,以裸 IP 报文形式发给 C
最后发现似乎是
net.core.default_qdisc = fq
可能触发mpls包不转发的问题,sysctl里不加这一条似乎就正常了。。很迷惑的问题,因为总是开着bbr所以之前没意识到这个问题
在全网开启no-php-flag的时候
如果加上这条,对于gre隧道,可能导致包在目标虚拟网卡转发的时候,直接被目标虚拟网卡drop掉(计数增加),gre外层的网卡看不到包;对于tap网卡,则是在转发过程中被丢掉了(即在目标网卡中看不到包)